Building a Scalable Distributed LangGraph on Kubernetes
Scaling AI agent workflows from a single Python script on your laptop to a highly available, enterprise-grade distributed system is one of the biggest challenges in production AI. Native LangGraph executes graphs synchronously or asynchronously within a single process. But what happens when an individual agent node requires heavy computation, or when you need to process hundreds of parallel workflows?
In this post, we will explore the architecture of a Scalable Distributed LangGraph System running on Kubernetes. We will use a real-world use case, an automated Insurance Claim Processing system to demonstrate how to decouple graph nodes so that each execution step is handled by different workers across a distributed cluster.
The Architecture: Distributing the Graph
To transition from a monolithic process to a distributed architecture, we combined native LangGraph orchestration with Celery for task dispatch and Redis for state checkpointing. This ensures we distribute the actual node executions while maintaining a strongly consistent graph state.
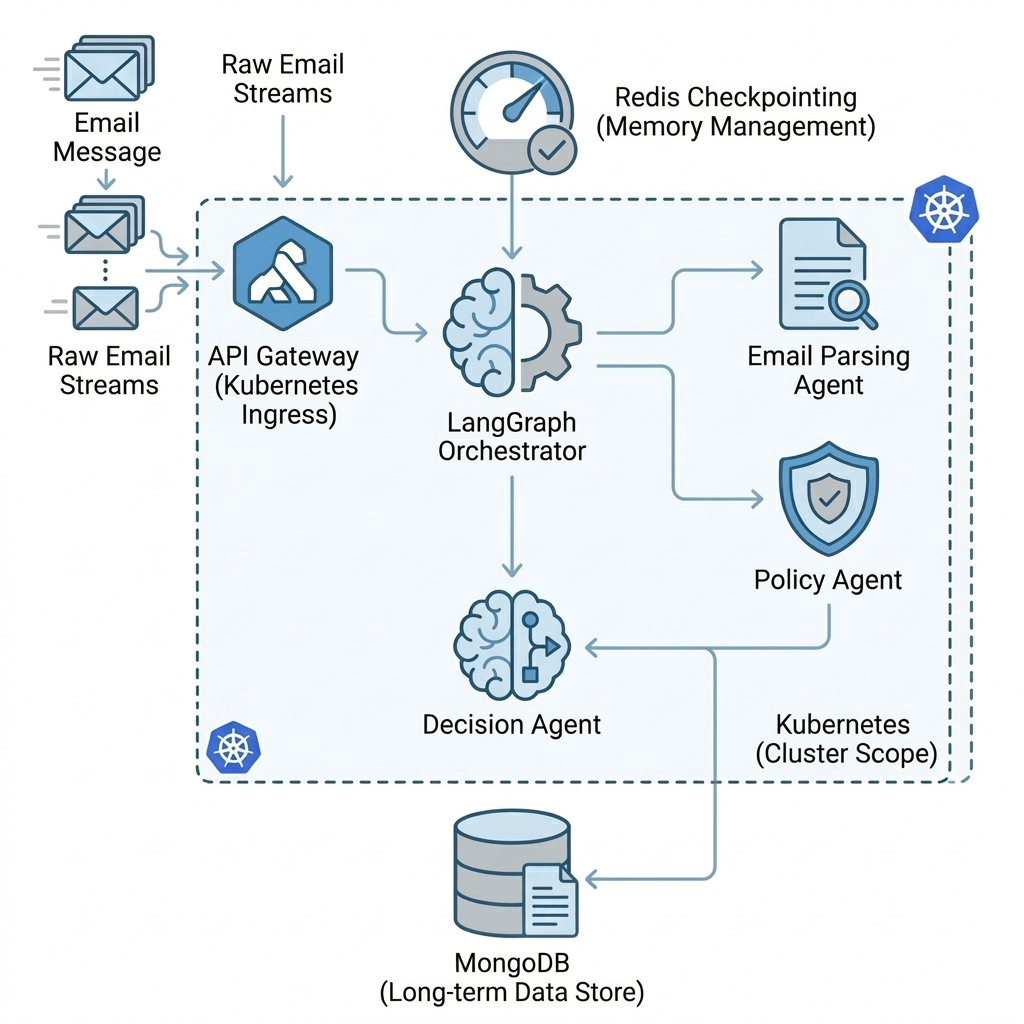
Our distributed architecture relies on three core pillars:
1. State Management: Deep Persistence
AI agents need memory. We leverage langgraph-checkpoint-redis to provide robust, thread-safe state persistence. Every time an agent finishes its task, the exact state of the workflow (the “graph”) is serialized and saved in Redis. Any worker, anywhere in the cluster, can pick up the thread_id and resume the workflow precisely where it left off.
2. Actor Dispatch: Event-Driven Handoffs
Instead of a single orchestrator executing graph.invoke(), we map specific LangGraph nodes to distinct message queues using Celery. When Node A completes, it computes the next step and drops a message onto Node B’s specific queue via the Celery broker.
3. Execution: Kubernetes Worker Pods
Worker deployments in our Kubernetes cluster are not generic. They are specialized pods listening to specific queues. They load the state from Redis, run the LangGraph node logic, update the state, and yield execution back to the queue broker automatically.
Business Usecase: Insurance Claim Processing
To put this architecture to the test, we built a Multi-Agent system that processes insurance claims from end to end. The pipeline resembles a human claims department, divided into specialized roles.
Here is the flow of the process:
- API Gateway: The entry point. It receives a JSON payload representing the claim email and returns a tracking
thread_idback to the client immediately. - Email Agent (
email_queue): The parser. It receives the raw text, uses an LLM to understand the context, and extracts structured data like thepolicy_id,claim_amount, and a concise incident description. - Policy Agent (
policy_queue): The validator. It takes the parsed metadata and checks the MongoDB policy database to verify coverage limits, deductibles, and active status. - Decision Agent (
decision_queue): The adjudicator. Combining the extracted context and the MongoDB policy rules, it reasons through the claim to reach a final Approve, Reject, or Escalate decision.
Provider Agnosticism & Mocking
When building enterprise systems, you want to avoid vendor lock-in. Similar to the “Bring Your Own Key” (BYOK) model we have utilized in other architectures, this system abstracts the LLM integration layer behind a dynamic LLM_PROVIDER environment variable.
You can easily toggle between providers simply by updating the variables in your Kubernetes manifest or local .env file:
- OpenAI: Set
LLM_PROVIDER=openaiandOPENAI_API_KEY=your_key - Groq: Set
LLM_PROVIDER=groq(excellent for high-speed parsing tasks) - Ollama: Set
LLM_PROVIDER=ollamafor fully local inference.
Furthermore, it natively supports a “mock” mode, allowing developers to execute integration testing and deployment validation without spending a single cent on API keys.
Running It Yourself
The beauty of declarative Kubernetes manifests is how easily this complex orchestration spins up. Locally, you can deploy the entire ecosystem using minikube:
# Apply persistent data stores
kubectl apply -f k8s/mongo.yaml
kubectl apply -f k8s/redis.yaml
# Apply the Gateway and API
kubectl apply -f k8s/api.yaml
# Deploy the specialized Celery workers
kubectl apply -f k8s/workers.yaml
Once running, you can submit a claim by HTTP POSTing to the exposed API Gateway pod and tracking the lifecycle of the LangGraph execution asynchronously.
Conclusion
By decoupling the execution plane (Kubernetes & Celery) from the orchestration plane (LangGraph) and unifying them with a centralized state (Redis), we eliminate the bottlenecks of monolithic AI applications. This architecture enables scaling individual agents independently, for instance, spinning up 10 extra instances of the email_queue worker during high-traffic bursts without touching the policy_queue workers.
Check out the code on GitHub to see how you can deploy your own distributed AI graphs!