Lambda & Kappa Architecture with Azure Databricks
Technology implementation of Lambda & Kappa Architecture Patterns
In the year 2017, I wrote one article about architecture patterns for IoT & Analytics. The article was about the comparison between Lambda & Kappa architecture and it was not about what technologies to use to implement those architecture patterns, you can read that article from here. The technology landscape keeps changing in the analytics domain and what architecture implementation was possible 2 years before could be better implemented with current/latest technologies so I thought of writing this article and provide insight into possible technology implementation for Lambda and Kappa architectures. The major component in described architectures is Databricks so below is a brief description of databricks.
What is Databricks?
Databricks is a unified platform for Data & AI and it is powered by Apache Spark™. It provides functionalities like reliable data engineering, machine learning, collaborative data science, etc. to simplify Data & AI.
What is Azure Databricks?
The Databricks uses multiple opensource technologies but to provide enterprise-grade scalability, the security it needs to provide fully managed cloud service. The Azure Databricks is the fully managed Databricks environment on Azure.
Lambda Architecture with Azure Databricks
In proposed Lambda Architecture implementation, the Databricks is a main component as shown in the below diagram.
There are two processing pipelines in Lambda Architecture, the one is Stream Processing (it is called Hot Path) and another one is Batch Processing (it is called Cold Path).
The “Hot Path” shows the Azure IoT Hub as a cloud gateway for IoT data being streamed from various devices. The streamed data can be further processed using Azure Databricks through Azure Event Hub where Databricks notebooks can be used to process the data and store it in the data lake. The streaming pipeline can apply machine learning algorithms through Azure Databricks and the calculation should be in real-time or near real-time so you may have restrictions on types of calculation you can do here. The result of these calculations along with original streamed data can be posted to the Azure Service bus topic so that various analytics clients can consume this streamed result. The data storage proposed for all types of raw, processed, and transformed data is Azure Data Lake Store Gen2.
The “Cold Path” shows the Azure Data Factory to ingest data in Data Lake, so Azure Databricks can process this data in Batch along with streamed data from a hot path. The batch-processed data should be stored in some kind of massively parallel processing engine with query capabilities so the proposed solution here is the Azure Synapse. Once processed data is available in Azure Synapse, various analytics clients can consume it for business applications. The Azure Synapse is an analytics service that brings together enterprise data warehousing and Big Data analytics, it gives the freedom to query data using either serverless on-demand or provisioned resources.
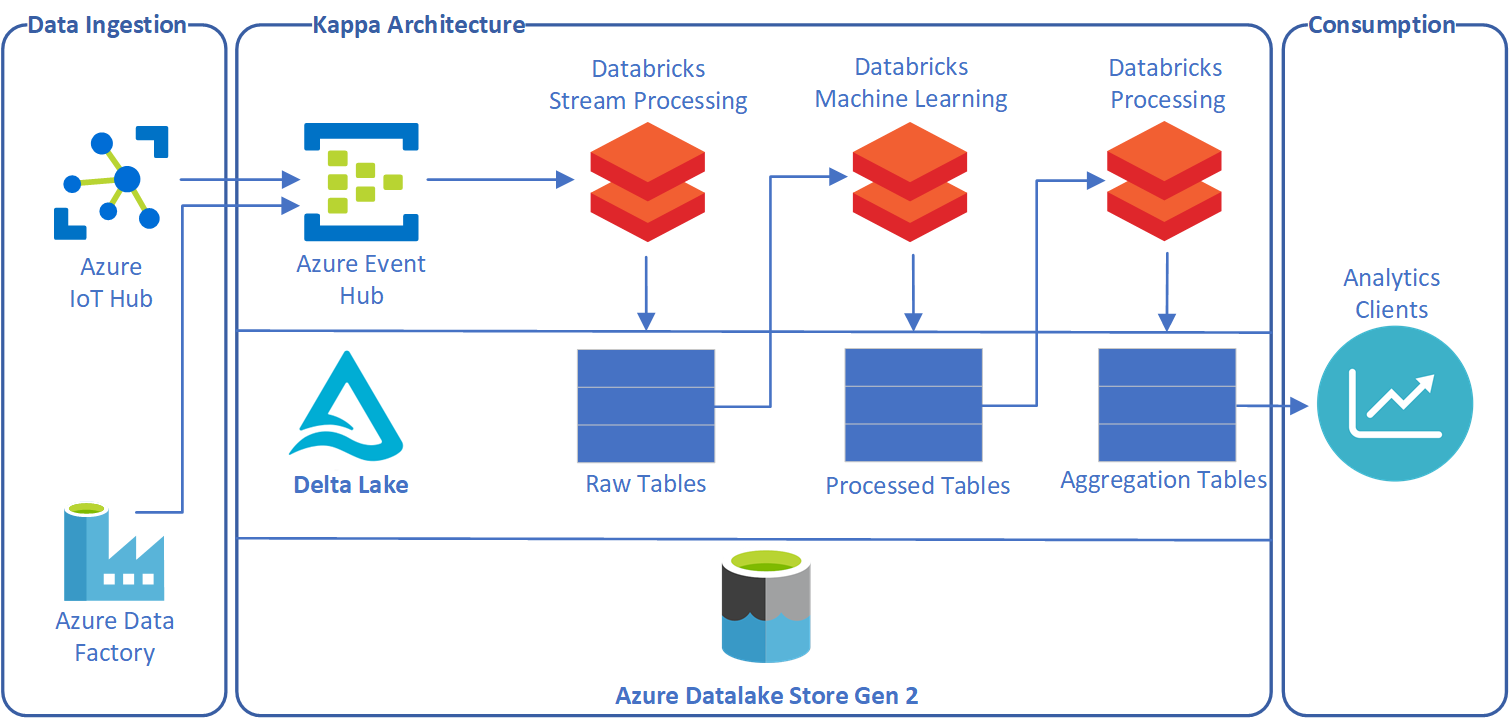
Kappa Architecture with Databricks
The Kappa Architecture suggests to remove the cold path from the Lambda Architecture and allow processing in near real-time.
As you can see in the above diagram, the ingestion layer is unified and being processed by Azure Databricks. To support queryable and aggregation of data, there needs to be a special type of storage and for this another open source technology comes to rescue - the Delta Lake. Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark™ and big data workloads. It is specifically more suitable for Databricks because you can create Delta Lake tables against the Databricks File System (DBFS). The DBFS can mount Azure storage like Azure Blob Storage and Azure Data Lake Storage. Delta Lake on Databricks provides configuration capabilities to design Delta Lake based on workload patterns and provides optimized layouts and indexes for fast interactive queries.
With Delta Lake capabilities, data can be processed using various Databricks notebooks and the processed result can be stored in various tables as a thin layer on top of the Data Lake. The data from Delta Lake tables can be queried using various clients with near-realtime and in batches as a unified pipeline. This unified approach brings less complexity by avoiding data management and multiple storage systems. The main advantage here is that queries can be performed on streaming and historical data at the same time.
Is the Kappa Architecture better than Lambda with Databricks?
As I mentioned earlier due to agility in the analytics technology landscape, it is better to evaluate various technologies and constantly improve the architecture (certainly without spending significant cost and resources). While selecting Lambda or Kappa architecture for IoT Analytics, there used to be suggestions like it all depends on use cases but with technologies like Databricks and Delta Lake I can confidently say that Kappa architecture is better if it is implemented with the right set of technologies.